Management expert Peter Drucker is quoted as saying, “You can’t manage what you don’t measure,” something most product managers or reporting nerds would agree with—especially when it comes to trying to improve the workflow of a development team. That said, not everyone is as chummy with Lean and Agile metrics as I am, which is completely understandable because I think about these things daily. The first thing to learn is that Lean and Agile metrics can be used for good (to streamline workflows, increase team efficiency, and rally a team toward a common goal)—as well as evil (to play the blame game, pit teams against each other, etc.).
We’ve all been part of projects where nothing was measured, and so it was difficult to know if progress was being made. This is not fun for everyone—nor is it truly Agile. You can’t increase agility if you don’t know how efficiently you’re working in the first place.
But if you’ve been practicing some form of Agile, Scrum, or Kanban, you’ve likely also experienced metrics being used incorrectly—either because the data being used to create them is not clean, or because the analysis of that data is drawing unsound conclusions and driving the wrong behaviors.
Tracking and analyzing sound Lean and Agile metrics can improve transparency across a team and help identify ways to improve the way your team is working.
It can help your team become more Lean and Agile by not only increasing speed, but by better preparing your system to manage setbacks. But first, you must have a clear, shared understanding across the team around what Lean and Agile metrics you’re using and why. Equally important, you must understand how you’re collecting them.
Using a Kanban board is essential for any team looking to improve its workflow. Think of it this way: If you can’t see it, you can’t measure it, and if you can’t measure it, how can you improve it? Using a digital Kanban board can help your team not only visualize its work, but also automate the collection and reporting of workflow metrics, giving you valuable insights that you can use to drive improvement efforts.
HERE ARE THE FIRST TWO OUT OF FIVE AGILE METRICS EVERY DEVELOPMENT TEAM SHOULD MEASURE.
LEAD TIME: HOW LONG DOES IT TAKE TO GET FROM “TO-DO”’ TO “DONE”?
What It Is: A measure of the total time it takes work to get delivered, from the time it’s requested to the time it’s delivered.
How It’s Measured: On Kanban boards—from the time a card is created to when it moves into the ‘Done’ column (reported on lead time reports, cycle time reports).
What It Tells Us: The perceived time that a piece of work took in the eyes of the customer (internal or external).
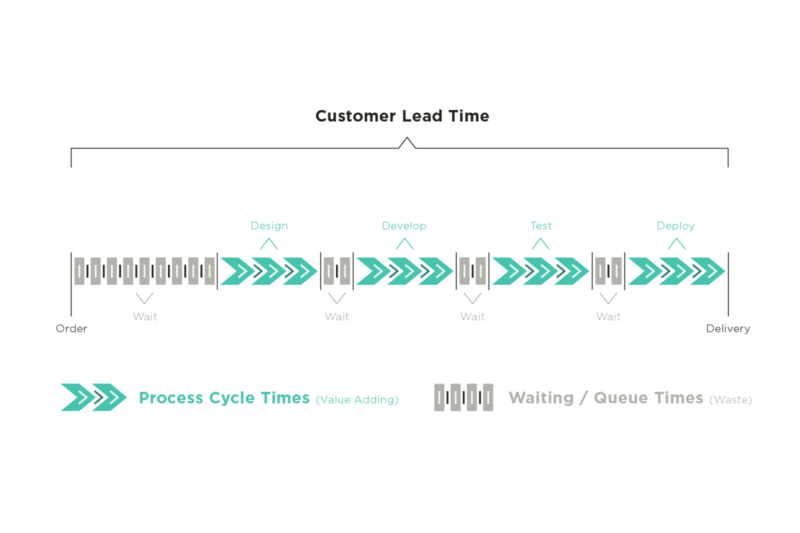
Lead time measures the total time it takes for work to move through the value stream, from the moment the work is requested to the time it’s delivered. It measures duration from beginning to end. This includes process time as well as time that work spends sitting in queues, or wait states.
We measure lead time by starting a timer when work is requested and stopping that timer when the work is delivered. Of course, it’d be challenging to manually measure lead times for every piece of work that moves through the system—which is why it’s crucial to find a tool that can do this for you, but more about that later.
Lead time is often used to provide estimates to customers. So, it’s critical that teams have an accurate understanding of their average lead times for different types of work. This is where it can get tricky.
Often, when we provide estimates, we think about how long it will take us to actively do the work. However, it’s likely that these active, value-adding steps only represent a fraction of your overall lead time. It’s more likely that between each of the process steps, the work will spend a considerable amount of time in queues, or wait states, and that the time spent in wait states will be greater than the active work time.
Typically, reducing lead times is a matter of optimizing handoffs between process steps, to minimize the time work spends in wait states. Limiting WIP across the team is one of the most effective ways to reduce wait states and thereby reduce overall lead times. Optimizing cycle times is equally important.
CYCLE TIME: HOW LONG DOES IT TAKE US TO…
What It Is: A measure of how long work takes to get from point A to point B within your process.
How It’s Measured: On Kanban boards—from the time a card enters one specified lane to the time it enters another specified lane (which lane depends on what part of your process you’re trying to measure).
What It Tells Us: How long certain portions of your process might take; therefore, giving insight into where work gets stuck in your process and how to improve flow.
Both lead time and cycle time help us understand how long work takes to flow through our Agile workflows, but they measure different segments of the process. While lead time measures the total time a work item spends in our system, cycle time measures how long it takes a work item to get from point A to point B.
Since cycle time can be measured from any two starting and ending points on a Kanban board, it’s common for several categories of cycle time to exist on one board (e.g., design cycle time, development cycle time, QA cycle time, etc.).
Similar to measuring lead times, we can measure cycle times by starting a timer when work enters a certain lane on our board and stop it when it moves out of that lane.
Lean and Agile teams can measure cycle times on each of the steps in their process and experiment with ways to reduce them. For example, if you find that your testing cycle time is considerably longer than the other steps in your process, you can try reducing the WIP limit of the testing step, assigning an additional team member to the testing step, or simplifying requirements for testing, allowing the team to move through that step faster.
It might be that within a specific step, there are several review cycles that aren’t visualized. Visualizing these review cycles as their own individual steps can help teams get a more accurate understanding of where work gets stuck.
Now, back to finding a tool that can measure lead and cycle times for you—Planview AgilePlace can be just that tool. Not only is it able to do the measuring for you, but through features like Kanban boards, you will be able to easily prioritize and visualize your work in progress, as well as that of other team members. If you’re interested to learn more, register for a free trial of Planview AgilePlace today!